

最終更新日 2025年2月2日

Linuxのパフォーマンス解析になぜperfコマンドを使うのか?
Linuxの運用をしていると、「特定のプロセスが重い」「システムのレスポンスが悪い」といった問題に遭遇することが多い。こうした問題の原因を特定するために、普段から top, vmstat, iostat, sar などの基本的なツールを使っているエンジニアは多いだろう。
しかし、これらのツールだけでは 「なぜ遅いのか」「どの関数や処理がボトルネックになっているのか」 までは分からないことがある。特にCPU負荷の原因を深く調査する必要がある場合、Linuxのperfコマンド が役立つ。
ここでは、perfコマンドの基本的な役割と、従来のツールとの違いについて説明する。
先輩、パフォーマンス調査で top や vmstat はよく使うんですが、perf って何ができるんですか?
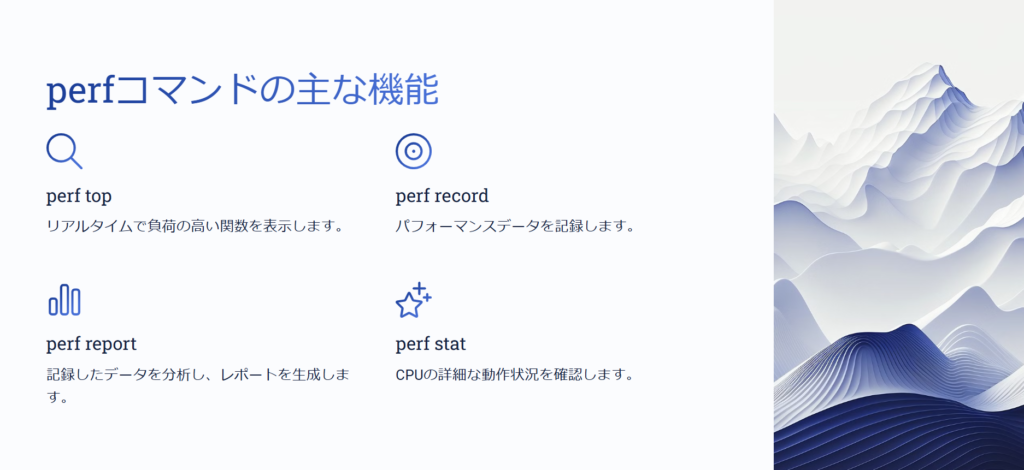
簡単に言うと、Linuxカーネルが提供するパフォーマンス計測ツールで、CPUやメモリの詳細なプロファイリングができる ツールだよ。例えば perf top を使えば、負荷の高い関数をリアルタイムに表示できるし、perf record と perf report を使えば、どの関数がどれだけCPUを使っているか詳細に分析できる。
なるほど、つまり top ではプロセス単位の負荷しか見えないけど、perf を使うと関数レベルまで掘り下げられるんですね。
そういうこと。特に perf はカーネルレベルの情報も取得できるから、ユーザープロセスだけでなく、システム全体のボトルネックを調査するのにも向いている。
perfコマンドの基本的な使い方は以下の記事で紹介しているのでよかったら見てみてください!


従来のツールとperfの違い
パフォーマンス調査にはいくつかのツールがあるが、それぞれの特徴を簡単に比較すると以下のようになる。
従来のツールとperfの違い
確かに、top ではプロセスのCPU使用率は分かりますが、どの関数が原因なのかまでは分かりませんね。
そうだね。例えば、アプリケーションが重いときに top で見ると、特定のプロセスがCPUを使いすぎているのは分かるけど、perf を使えば どの関数やコードが原因なのか まで特定できるんだ。

事例紹介|perfコマンドを活用したリアルなトラブル対応
ここからは、実際に現場で遭遇したパフォーマンス問題を Linuxのperfコマンドを使ってどのように特定・解決したのか について紹介する。
ケース1 CPU使用率が高いプロセスの特定
ある日、社内のWebアプリケーションの動作が急激に遅くなったという報告が上がった。topコマンドで確認すると、あるプロセスがCPUを異常に消費している ことが判明した。しかし、なぜそのプロセスがCPUを大量に使っているのかは分からない。
このような場合、perfコマンドを使ってプロセスの詳細なCPU使用状況を分析することで、どの関数がボトルネックになっているのかを特定できる。
先輩、サーバーが重いって報告が来たんですけど、top で見ると myapp というプロセスがCPUを80%以上使っています。でも、どの処理が負荷をかけているのかが分かりません…
top でプロセス単位の負荷は分かるけど、どの関数が問題なのかは分からないよな。こういうときは perf top を使ってみよう。

調査 perf top で負荷の高い関数を特定
まず、リアルタイムでどの関数がCPUを多く使っているかを調べるために、perf top を実行した。
sudo perf topすると、次のような出力が得られた。
40.12% myapp [.] process_data
30.89% myapp [.] parse_request
15.47% libc-2.31.so [.] malloc
10.00% myapp [.] database_queryこの結果から、myapp の process_data という関数がCPUを最も消費していることが分かった。
この process_data という関数が一番CPUを使っていますね。でも、具体的に何が原因なんでしょうか?
perf top は関数レベルの情報は分かるけど、詳しい実行時間やどこで時間がかかっているかまでは分からない。次に perf record を使って詳細なプロファイリングをしよう。
詳細分析 perf record と perf report を活用
次に、perf record を使ってアプリケーションの動作を一定時間記録し、その結果を perf report で分析した。
sudo perf record -p $(pgrep myapp) -g -- sleep 10
sudo perf reportこの結果、process_data 内の特定のループ処理がCPUを大量に消費していることが判明した。
# Overhead Samples Command Shared Object Symbol
# ........ ....... ....... ............... .....................
40.12% 1000 myapp myapp process_data
30.89% 700 myapp myapp parse_request
15.47% 400 myapp libc-2.31.so malloc特に malloc が高頻度で呼び出されていることから、メモリ確保のコストが高く、CPUリソースを圧迫している ことが分かった。
malloc が頻繁に呼ばれているせいで process_data の処理が遅くなっているみたいですね。メモリ確保の最適化を考えたほうがよさそうです。
そうだな。例えば、頻繁にメモリ確保と解放を繰り返す処理があるなら、メモリプールを使うことで効率化できるかもしれない。
perfコマンドのオプションの使い方は以下の記事で紹介しているのでよかったら見てみてください!
スポンサーリンク
解決策 メモリ管理の最適化
この process_data 関数では、ループのたびに malloc でメモリ確保を行い、都度 free で解放していた。このような処理は、ヒープメモリの断片化を引き起こし、パフォーマンス低下の原因になる。
そこで、メモリプールを導入し、一定サイズのメモリを事前確保して使い回すように変更した。
// 修正前:毎回mallocとfreeを実行
void process_data() {
for (int i = 0; i < 100000; i++) {
char *buffer = (char *)malloc(1024);
// データ処理
free(buffer);
}
}
// 修正後:メモリプールを利用
void process_data() {
char *buffer_pool = (char *)malloc(1024 * 100000);
for (int i = 0; i < 100000; i++) {
char *buffer = buffer_pool + (i * 1024);
// データ処理
}
free(buffer_pool);
}この修正後、CPU使用率は 80% → 40% に低下し、アプリケーションのレスポンスが改善された。
malloc の呼び出し回数を減らすだけで、こんなにCPU負荷が下がるんですね。
メモリ管理は意外とCPU負荷に影響を与えるんだ。特に高頻度なデータ処理ではメモリプールを活用するのが効果的だよ。

まとめ
- 問題 アプリケーションのCPU使用率が異常に高く、レスポンスが遅い
- 調査
perf topで負荷の高い関数 (process_data) を特定perf record+perf reportでmallocの頻繁な呼び出しがボトルネックと判明
- 解決策 メモリプールを導入し、メモリ確保の回数を削減
このように、perfコマンドを使うことで 「CPU使用率が高い」→「どの関数が負荷をかけているか」→「なぜ負荷が高いのか」 を段階的に調査し、最適な解決策を導き出すことができる。
次の事例では、システム全体のレスポンスが悪化した際に、perfを使ってどの処理が遅延しているかを特定したケース を紹介する。
ケース2 システム遅延の原因を特定する
ある日、社内のWebアプリケーションが全体的に遅くなっているという報告があった。調査のために top や vmstat を確認したが、CPU使用率はそれほど高くなく、メモリの使用状況も特に問題はなさそうだった。
「CPU使用率が高いわけでもないのに、なぜかアプリのレスポンスが遅い」
このようなケースでは、CPU使用率だけでなく、CPUがどのように動作しているかを詳しく調べる必要がある。このとき役に立つのが perf stat だ。
先輩、Webアプリのレスポンスが全体的に遅いって報告がありました。でも、top を見てもCPU使用率はそれほど高くなくて、負荷が原因には見えないんです。
CPU使用率だけじゃ問題の本質は分からないことがある。例えば、CPUは使われていないのに、メモリやキャッシュの問題で処理が遅くなることがあるんだ。
CPUが100%に張り付いているなら分かりやすいんですが、負荷が低いのに遅いのは原因が特定しづらいですね…。
こういうときは perf stat を使うと、CPUの実際の動作状況が見えてくる。

調査 perf stat でCPUの詳細な動作を確認
まず、遅延が発生している myapp プロセスの動作を分析するために、perf stat を実行した。
sudo perf stat -p $(pgrep myapp) -- sleep 1010秒間の計測後、次のような結果が出た。
Performance counter stats for process 1234 (myapp):
2,500,000 cycles
1,000,000 instructions
25.00 instructions per cycle
500,000,000 cache-references
400,000,000 cache-misses
10.002424199 seconds time elapsed特に注目すべきは cache-misses(キャッシュミス)が400,000,000回 と異常に多いことだった。
キャッシュミスの回数がすごく多いですね…。これが原因ですか?
そうだな。通常、CPUの処理はキャッシュを使うことで高速化される。でも、キャッシュミスが多発すると、CPUがメインメモリからデータを読み込むことになり、処理速度が大幅に落ちる。
CPU自体の負荷は低いのに、キャッシュミスのせいで待ち時間が増えていたんですね。
その通り。これが ‘CPUスタル(CPUが仕事をせず待機する時間)’ の原因になっているんだ。
問題の原因 データのアクセスパターンが非効率だった
アプリケーションのコードを確認すると、大量のデータを逐次処理するループ処理があり、メモリアクセスのパターンが悪かった ことが分かった。
// 修正前:キャッシュ効率が悪いアクセス
int matrix[1000][1000];
for (int i = 0; i < 1000; i++) {
for (int j = 0; j < 1000; j++) {
sum += matrix[j][i]; // 列優先のアクセス
}
}このコードでは、行ではなく列ごとにアクセスしているため、CPUキャッシュに乗りにくい。メモリは通常、行単位でキャッシュされるため、このようなアクセスをするとキャッシュミスが多発する。
そこで、アクセスの順序を最適化 し、キャッシュに乗りやすくした。
// 修正後:キャッシュ効率が良いアクセス
int matrix[1000][1000];
for (int i = 0; i < 1000; i++) {
for (int j = 0; j < 1000; j++) {
sum += matrix[i][j]; // 行優先のアクセス
}
}この修正後、perf stat の cache-misses の数が 400,000,000 → 50,000,000 に減少し、アプリケーションのレスポンスが劇的に向上した。
コードのアクセス順を変えるだけで、キャッシュミスの回数が減るんですね。意外と簡単な改善策でした。
こういうメモリアクセスの最適化は、データ処理が多いアプリケーションでは重要なんだ。CPU使用率だけ見ていると見逃しがちだから、perf stat のようなツールを使って内部の動きを見ることが大事だよ。

まとめ
- 問題 CPU使用率は低いのに、Webアプリのレスポンスが悪化
- 調査
perf statを実行し、cache-missesが異常に多いことを特定
- 原因 メモリアクセスのパターンが悪く、キャッシュミスが多発
- 解決策
- 行単位でデータを処理するようにコードを修正し、キャッシュ効率を向上
- キャッシュミスを削減し、アプリケーションの処理速度を改善
このように、CPU使用率だけでは見えないボトルネックを perf stat で可視化することで、適切な最適化を行うことができる。
次の事例では、ディスクI/Oの影響がアプリのパフォーマンスに与えた影響を perf trace を使って調査したケース を紹介する。
ケース3 ディスクI/Oの影響を評価する
ある日、社内のデータ処理バッチが いつもより極端に遅くなっている という報告が上がった。通常であれば30分程度で完了する処理が、2時間経っても終わらない状態だった。
まずは top コマンドを確認したが、CPU使用率はそれほど高くなく、vmstat でメモリやCPUの負荷を見ても特に異常は見られなかった。しかし、iostat でディスクI/Oの状況を確認すると、ディスクのI/O待ち時間(await)が異常に長くなっている ことが分かった。
このようなケースでは、ディスクI/Oがボトルネックになっている可能性が高いため、perf trace を使ってアプリケーションがどのようなI/O操作をしているのかを詳しく調査することにした。
先輩、データ処理バッチの実行時間が異常に長くなっています。でも、top を見てもCPUはそんなに使われていなくて、何が原因なのか分かりません。
CPUがボトルネックになっていないなら、I/Oが原因かもしれない。iostat を見て、ディスクの待ち時間を確認してみよう。
iostat -x 1 を実行したら、await の値が1000ms以上になっていました。ディスクのI/O待ち時間が長すぎるみたいです。
それは怪しいな。次に perf trace を使って、どのシステムコールがディスクI/Oを発生させているのか調べよう。

調査 perf trace でシステムコールを監視
perf trace を実行し、遅延が発生しているバッチプロセス(mybatch)がどのようなシステムコールを実行しているのかを調査した。
sudo perf trace -p $(pgrep mybatch)すると、次のような出力が得られた。
1234.567 (mybatch) read(3, 0x7ffc5d8a0000, 4096) = 4096
1234.568 (mybatch) read(3, 0x7ffc5d8a1000, 4096) = 4096
1234.569 (mybatch) fsync(3) = 0
1234.570 (mybatch) read(3, 0x7ffc5d8a2000, 4096) = 4096
1234.571 (mybatch) read(3, 0x7ffc5d8a3000, 4096) = 4096
1234.572 (mybatch) fsync(3) = 0特に fsync() の呼び出しが頻繁に発生していることに注目した。
fsync(3) = 0 っていうシステムコールがすごく多いですね。これは何をしているんですか?
fsync() は、データをディスクに確実に書き込むためのシステムコールだ。頻繁に呼び出されると、ディスクI/Oの負荷が高くなる。
なるほど。ということは、この処理が頻繁にディスク書き込みをしているせいで、I/Oが詰まっているんですね。
そうだな。バッチ処理のコードを見て、fsync() をどこで使っているか確認しよう。
perfコマンドの出力結果の見方は以下の記事で紹介しているのでよかったら見てみてください!


問題の原因 fsync() の頻繁な呼び出し
バッチ処理のコードを確認すると、ログファイルに書き込むたびに fsync() を実行していた。
// 修正前:毎回fsyncを実行
void write_log(const char *message) {
FILE *fp = fopen("/var/log/mybatch.log", "a");
if (fp) {
fprintf(fp, "%s\n", message);
fflush(fp);
fsync(fileno(fp)); // 毎回ディスクに強制書き込み
fclose(fp);
}
}このコードでは、ログを1行書き込むたびに fsync() を実行しているため、ディスクへの書き込みが頻発し、I/O待ち時間が長くなっていた。
解決策として、バッファを活用し、一定間隔でまとめて書き込む ように変更した。
// 修正後:一定間隔でfsyncを実行
void write_log(const char *message) {
static FILE *fp = NULL;
static int count = 0;
if (!fp) {
fp = fopen("/var/log/mybatch.log", "a");
}
if (fp) {
fprintf(fp, "%s\n", message);
count++;
if (count % 100 == 0) { // 100回に1回fsyncを実行
fflush(fp);
fsync(fileno(fp));
}
}
}この修正後、ディスクI/Oの負荷が大幅に軽減され、バッチ処理の実行時間が 2時間 → 35分 に改善された。
ログの書き込みをまとめるだけで、こんなに速くなるんですね。
fsync() は確実にデータを書き込むための大事な操作だけど、頻繁に実行するとディスク負荷が高くなる。バッファリングをうまく活用するのがポイントだよ。

まとめ
- 問題 バッチ処理の実行時間が極端に長くなった
- 調査
iostatでディスクI/O待ち時間 (await) の異常な増加を確認perf traceでfsync()の頻繁な呼び出しを特定
- 原因 ログ書き込みごとに
fsync()を実行し、ディスクI/Oが過負荷 - 解決策
- ログの書き込みをバッファリングし、
fsync()の回数を削減 - ディスク負荷を抑えることで、処理時間を 2時間 → 35分 に短縮
- ログの書き込みをバッファリングし、
このように、ディスクI/Oの影響は top や vmstat では見えにくいが、perf trace を使うことで どのシステムコールがボトルネックになっているかを特定できる。

perfコマンドはどんな場面で役立つのか?
perfコマンドは、主に CPU・メモリ・I/O などのパフォーマンスボトルネックを特定する のに役立つ。
実際のトラブル対応事例を振り返ると、以下のような場面で有効だった。
| ケース | 問題の症状 | 使用したperfコマンド | 特定した原因 | 解決策 |
|---|---|---|---|---|
| CPU負荷が高い | 特定のプロセスがCPUを占有 | perf top, perf record | malloc() の多発によるCPU負荷 | メモリプールの導入 |
| システム遅延が発生 | CPU使用率は低いが遅い | perf stat | キャッシュミスの多発 | メモリアクセスの最適化 |
| ディスクI/Oが遅い | バッチ処理が遅延 | perf trace | fsync() の頻繁な実行 | ログ書き込みのバッファリング |
このように、perfを使うことで 「どこに問題があるのか」→「なぜその問題が起きているのか」 まで特定しやすくなる。
今まで top や vmstat でしか調査していませんでしたが、perf を使うとより細かく原因を特定できますね。
そうだな。単に ‘CPUが高い’ だけじゃなくて、perf を使えば ‘どの関数が負荷をかけているか’ まで分かる。特にパフォーマンス問題を迅速に解決したいときに役立つ。
でも、perfコマンドってたくさんオプションがあって、どれを使えばいいのか迷いそうです。
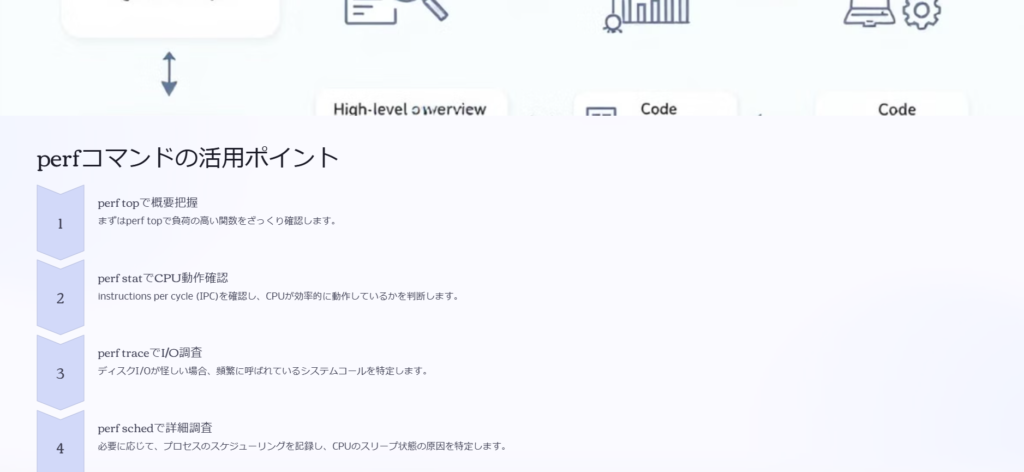
最初は perf top で負荷の高い関数をざっくり確認して、必要に応じて perf stat や perf record を使う、という流れを覚えておくといいよ。

現場での活用ポイントと注意点
実際に現場でperfを活用する際に、気をつけるべきポイントをいくつかまとめる。
1. いきなり perf record を実行しない
perf record は詳細なプロファイリングができるが、ログの取得に時間がかかる ため、まずは perf top で概要をつかむのが効率的。
2. perf stat でCPUの動作状況をチェックする
CPU使用率が低いのに遅い場合は、キャッシュミスやブランチミス が原因のことが多い。perf stat で instructions per cycle (IPC) を確認すると、CPUが効率的に動作しているかが分かる。
3. ディスクI/Oが怪しいときは perf trace を使う
perf trace で どのシステムコールが頻繁に呼ばれているか を見ると、I/Oのボトルネックを特定しやすい。fsync() のようなディスク書き込み処理が過剰に発生していると、I/Oが詰まる原因になる。
4. カーネルレベルの調査が必要なら perf sched も活用する
perf sched record は プロセスのスケジューリング を記録できるため、CPUがスリープ状態に入る原因を特定できる。
perf って便利ですが、どこまで詳細に調査するべきか迷いそうです。
基本は ‘軽い調査 → 詳細調査’ の順番でやるといいよ。最初に perf top で概要をつかんで、問題の兆候があれば perf stat や perf trace で掘り下げる。perf record は最後の手段だ。
なるほど。最初から詳細なログを取ると、余計な時間がかかるんですね。
そういうこと。トラブル対応のときは 素早く問題の全体像を把握することが重要 だからな。

ゴリタン
インフラエンジニアとして、ネットワークとサーバーの運用・保守・構築・設計に幅広く携わり、
現在は大規模政府公共データの移行プロジェクトを担当。
CCNPやLPICレベル3、AWSセキュリティスペシャリストなどの資格を保有しています。