

最終更新日 2025年3月10日

journalctl コマンドの基本と使い方
Linuxのログ管理において、journalctl コマンドはシステムログを簡単に確認できる強力なツールです。トラブルシューティングやパフォーマンス分析をする際に、ログを適切に確認できることはエンジニアにとって必須のスキルです。
本記事では、journalctl の基本構文から頻出オプション、出力結果の読み取り方までをわかりやすく解説します。
- journalctl コマンドの基本構文を理解しよう
- journalctl コマンドの頻出オプション一覧|活用シーン別に解説
- その他の全オプション一覧とオプションの解説
- journalctl コマンドの出力結果の読み取り方
- journalctl のよく出力されるログ20選とその意味
- まとめ
journalctl コマンドの基本構文を理解しよう
journalctl コマンドは「systemd」のログを管理するためのコマンドです。
デフォルトでは /var/log/journal/ に保存されているバイナリ形式のログを読み取り、人間が読める形式に変換して出力します。
基本的な構文
journalctl [オプション] [フィルタ]オプションを指定しない場合、すべてのログ を時系列順で出力します。
journalctl を実行したら大量のログが表示されてしまいました。どうすればいいですか?
基本構文だけだと全ログが表示されるから、オプションを使って適切に絞り込むのがポイントだよ。たとえば最新のログだけ見たいなら journalctl -n 50 で直近50件のログを表示できるよ。
![journalctlコマンドの基本
基本構文
journalctl [オプション] [フィルタ]
オプションを指定しない場合、すべてのログを時系列順で出力します。
ログの保存場所
デフォルトでは/var/log/journal/に保存されています。
バイナリ形式のログを人間が読める形式に変換して出力します。](https://www.goritarou.com/wp-content/uploads/2025/03/image-48-1024x327.png)
journalctl コマンドの頻出オプション一覧|活用シーン別に解説
journalctl には便利なオプションが多数あり、状況に応じて適切に使い分けることが重要です。
以下に実務でよく使うオプションを一覧で紹介します。
| オプション | 説明 |
|---|---|
-n [数] | 最新の [数] 件のログを表示 |
-f | リアルタイムでログを監視(tail -f のような動作) |
-u [サービス] | 指定したサービスのログのみを表示 |
--since / --until | 指定した時間範囲のログを表示 |
-p [優先度] | 指定した重要度のログのみ表示 (0=緊急, 7=デバッグ) |
特定のサービスのログだけ確認するにはどうすればいいですか?
journalctl -u nginx のように -u オプションを使えば、そのサービスのログだけを表示できるよ。例えば、Nginxのログをリアルタイムで確認するなら journalctl -u nginx -f を使うと便利だよ。
エラーや警告だけを表示するにはどうすればいいですか?
-p オプションを使えば、指定した優先度以上のログだけを表示できるよ。例えば、エラー以上のログを見たいなら journalctl -p 3 ってやればOK。
![頻出オプション一覧
-n [数]
最新の[数]件のログを表示
-f
リアルタイムでログを監視(tail -fのような動作)
-u [サービス]
指定したサービスのログのみを表示
--since / --until
指定した時間範囲のログを表示
-p [優先度]
指定した重要度のログのみ表示 (0=緊急, 7=デバッグ)](https://www.goritarou.com/wp-content/uploads/2025/03/image-60-1024x468.png)
その他の全オプション一覧とオプションの解説
| オプション | 実行例 | 説明 |
|---|---|---|
--system, --user | journalctl --system | システム全体のログを表示(--user は現在のユーザーのログのみ) |
-M, --machine= | journalctl -M my-container | 特定のコンテナ(仮想環境)のログを表示 |
-m, --merge | journalctl -m | ローカル+リモート(外部サーバー)のすべてのログを統合して表示 |
-D DIR, --directory=DIR | journalctl -D /var/log/journal | 指定したディレクトリ(フォルダ)のジャーナルファイルを使用 |
-i GLOB, --file=GLOB | journalctl -i /var/log/journal/* | 指定したパターン(ワイルドカード)に一致するログファイルのみ使用 |
--root=ROOT | journalctl --root=/mnt/system-root | 指定したディレクトリのログを読み取る(例:別のシステムのログ) |
--image=IMAGE | journalctl --image=disk.img | ディスクイメージ(バックアップファイル)のログを読み取る |
--namespace=NAMESPACE | journalctl --namespace=my_logs | 指定したジャーナルのネームスペース(区分)を使用 |
-S, --since= | journalctl --since "2024-03-01" | 指定した日付以降のログを表示 |
-U, --until= | journalctl --until "2024-03-05" | 指定した日付以前のログを表示 |
-b, --boot | journalctl -b -1 | 1つ前のブート(再起動)のログを表示 |
-u, --unit=UNIT | journalctl -u nginx | 特定の systemd ユニット(例:nginx)のログを表示 |
-t, --identifier=SYSLOG_IDENTIFIER | journalctl -t sshd | 指定した syslog ID(ログを記録したプログラム)のログを表示 |
-p, --priority= | journalctl -p 3 | 指定した優先度(ログの重要度レベル)のログのみを表示(3=エラー 以上) |
-g, --grep= | journalctl -g "failed" | メッセージ(ログの内容)の正規表現検索("failed" を含むログのみ表示) |
-k, --dmesg | journalctl -k | カーネルメッセージ(Linuxのシステムコア部分のログ)のみ表示 |
-o, --output= | journalctl -o json-pretty | 出力フォーマットを変更(例:JSON 形式で見やすく表示) |
-n, --lines= | journalctl -n 50 | 最新の50件のログを表示 |
-r, --reverse | journalctl -r | 新しいエントリを先に表示(時系列を逆順に) |
-f, --follow | journalctl -f | リアルタイムでログを表示(tail -f のように) |
--disk-usage | journalctl --disk-usage | ジャーナルファイルのディスク使用量を表示 |
--vacuum-size= | journalctl --vacuum-size=500M | ジャーナルファイルを500MB以下に削減 |
--vacuum-time= | journalctl --vacuum-time=7d | 7日より古いジャーナルファイルを削除 |
--vacuum-files= | journalctl --vacuum-files=5 | 5つ以上のジャーナルファイルを削除 |
--verify | journalctl --verify | ジャーナルファイルの整合性(壊れていないか)をチェック |
--sync | journalctl --sync | ジャーナルデータをディスクに即時書き込み |
--rotate | journalctl --rotate | 現在のジャーナルファイルをアーカイブし、新しいファイルを作成 |
--flush | journalctl --flush | メモリ上のログデータをディスクへ書き込む |
--list-boots | journalctl --list-boots | 過去のブート(再起動)の履歴を一覧表示 |
--list-invocations | journalctl --list-invocations -u nginx | 特定のユニットの起動履歴を表示 |
--header | journalctl --header | ジャーナルファイルのヘッダー情報(構造情報)を表示 |

journalctl コマンドの出力結果の読み取り方
journalctl の出力結果は「時刻」「ホスト」「プロセス情報」「メッセージ」の4つの要素で構成されます。
ログを正しく解析するために、各要素の意味を理解しましょう。
出力フォーマット
Mar 09 12:34:56 server-name systemd[1]: Started Nginx HTTP Server.
Mar 09 12:35:01 server-name sshd[10234]: Failed password for root from 192.168.1.10 port 54321 ssh2出力の各項目
- 日時(Mar 09 12:34:56) → ログが記録されたタイムスタンプ
- ホスト名(server-name) → ログを出力したマシンのホスト名
- プロセス情報(systemd[1] / sshd[10234]) → 実行したプロセス名とPID
- メッセージ内容(Started Nginx HTTP Server / Failed password…) → ログの具体的な内容
journalctl のログが読みにくいです。何か改善できますか?
-o オプションを使うとフォーマットを変更できるよ。例えば、JSON 形式で見たいなら journalctl -o json-pretty を試してみて。
システムが再起動したタイミングのログを見たいんですが、どうすればいいですか?
journalctl -b を使うと、現在のブート(起動)後のログだけを表示できるよ。前回のブートのログを見たいなら journalctl -b -1 ってやればいいよ。
![出力結果の読み取り方
日時
Mar 09 12:34:56 → ログが記録されたタイムスタンプ
ホスト名
server-name → ログを出力したマシンのホスト名
プロセス情報
systemd[1] / sshd[10234] → 実行したプロセス名とPID
メッセージ内容
Started Nginx HTTP Server → ログの具体的な内容](https://www.goritarou.com/wp-content/uploads/2025/03/image-51-1024x469.png)
journalctl のよく出力されるログ20選とその意味
| ログの例 | 意味(説明と補足) |
|---|---|
Mar 09 12:34:56 server systemd[1]: Started Nginx HTTP Server. | Nginx サーバーが起動した(systemd によるサービス管理の開始ログ) |
Mar 09 12:35:01 server sshd[10234]: Failed password for root from 192.168.1.10 port 54321 ssh2 | SSH のログイン失敗(不正アクセスの可能性) |
Mar 09 13:00:10 server kernel: CPU1: Core temperature above threshold, cpu clock throttled | CPU の温度が閾値を超えた(サーバーの負荷問題が疑われる) |
Mar 09 14:10:32 server systemd[1]: Failed to start MySQL Server. | MySQL サーバーの起動に失敗(設定ミスやポート競合が原因の可能性) |
Mar 09 14:45:23 server systemd[1]: Stopped Apache HTTP Server. | Apache サーバーが停止した(手動または障害による可能性) |
Mar 09 15:22:11 server systemd[1]: nginx.service: Main process exited, code=exited, status=1/FAILURE | Nginx が異常終了(設定ミスやポート競合の可能性) |
Mar 09 16:05:47 server kernel: Out of memory: Killed process 12345 (java) | メモリ不足により Java プロセスが強制終了(OOM-Killer による) |
Mar 09 16:50:30 server journalctl: No space left on device | ディスク容量不足(ログ肥大化や不要ファイル削除が必要) |
Mar 09 17:14:09 server systemd[1]: Reached target Multi-User System. | マルチユーザーモードに到達(システム起動完了) |
Mar 09 17:45:02 server systemd-logind[123]: New session 42 of user john. | ユーザー “john” が新しいセッションを開始(ログイン成功) |
Mar 09 18:10:29 server kernel: EXT4-fs error (device sda1): ext4_find_entry:1456: inode #2 | ファイルシステムエラー(ディスクの不良や fsck が必要) |
Mar 09 18:34:20 server systemd[1]: Unit apache2.service entered failed state. | Apache サーバーが異常終了(設定エラーやクラッシュの可能性) |
Mar 09 19:01:55 server kernel: eth0: Link is Down | ネットワークインターフェース(eth0)が切断(物理的な断線や設定変更の可能性) |
Mar 09 19:25:48 server kernel: eth0: Link is Up | ネットワークインターフェース(eth0)が接続(復旧または再接続) |
Mar 09 20:02:33 server systemd[1]: Starting Cleanup of Temporary Directories... | 一時ディレクトリ(/tmp)のクリーンアップ開始 |
Mar 09 20:30:00 server systemd[1]: Shutting down system. | システムがシャットダウンを開始(手動またはスケジュールによる可能性) |
Mar 09 21:10:45 server audit[1234]: ANOM_PROMISCUOUS dev=eth0 | ネットワークインターフェースがプロミスキャスモードに(パケットキャプチャや不正アクセスの兆候) |
Mar 09 21:40:12 server systemd[1]: Mounted /var/log. | /var/log ディレクトリがマウントされた(システム起動時の処理) |
Mar 09 22:15:50 server crond[4567]: (root) CMD (/usr/bin/backup.sh) | root ユーザーによる cron ジョブの実行(スケジュールされたバックアップ処理) |

まとめ
journalctl コマンドは Linux システムのログ管理において不可欠なツール です。
基本構文を理解し、適切なオプションを活用することで、トラブルシューティングやシステム監視がスムーズに行えます。特に 特定のサービスのログを絞り込んだり、リアルタイム監視を行う方法をマスターすることが重要 です。
実際の運用では、
- ログのフィルタリング (
-u,-p,--since) を適切に活用する - 出力フォーマット (
-o json-pretty) を変えて見やすくする - 特定のログのみ監視 (
-fでリアルタイム監視)
といったテクニックを身につけましょう。

journalctl コマンドの活用事例
journalctl を適切に活用すれば、トラブルシューティングの効率を大幅に向上させられます。
実際の業務では、システムの不具合や障害対応の際に journalctl を活用することで、迅速な原因特定と解決が可能です。ここでは、実際の業務での成功事例を紹介します。
ケース1:Nginx の突然の停止を特定し、迅速に復旧
ある日、運用している Web サーバーで Nginx が突然停止 しました。再起動しても数分後には停止する状況でした。
対応手順
1.サービスの状態を確認
systemctl status nginx→「Main process exited, code=exited, status=1」というエラーが表示
2.journalctl で詳細なログを取得
journalctl -u nginx --since "1 hour ago"→ 「no space left on device」エラーを発見
3.ディスク容量を確認
df -h→ ログファイルが肥大化し、ディスクがいっぱいになっていたことが判明
4.不要なログを削除し、Nginx を再起動
rm -rf /var/log/nginx/* systemctl restart nginx → 正常稼働を確認
Nginx の動作が不安定ですが、どこから調べればいいですか?
まず systemctl status nginx で概要を確認して、詳細なログは journalctl -u nginx でチェックしよう。

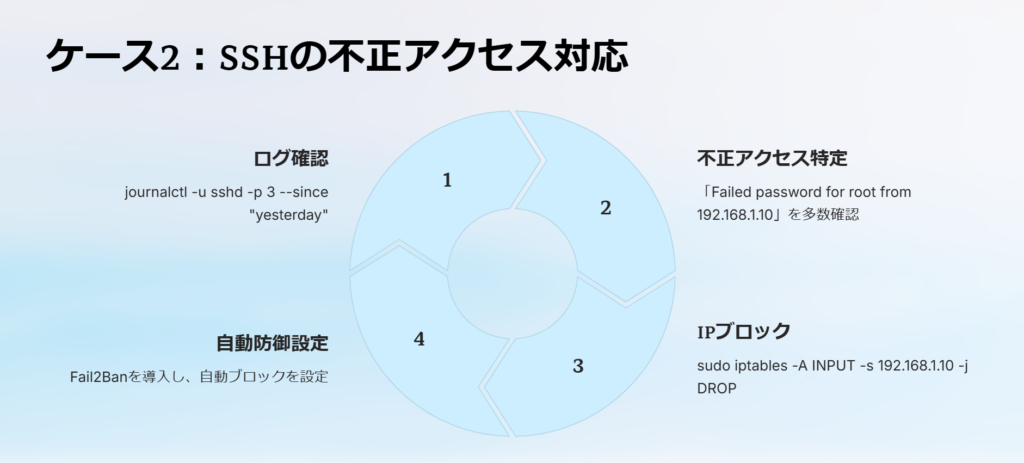
ケース2:SSH の不正アクセスを特定し、対策を実施
最近、SSH のログイン試行が急増 し、不正アクセスの可能性が浮上しました。
対応手順
1.journalctl で SSH の失敗ログを確認
journalctl -u sshd -p 3 --since "yesterday"→ 「Failed password for root from 192.168.1.10」 のログが多数記録
2.該当 IP アドレスをブロック
sudo iptables -A INPUT -s 192.168.1.10 -j DROP3.Fail2Ban を導入し、自動ブロックを設定
sudo apt install fail2banSSH のログイン試行が多い気がしますが、どこを見ればわかりますか?
journalctl -u sshd -p 3 でエラーログを確認できるよ。試行回数が多い IP はブロックしよう。
journalctl コマンドの失敗事例|よくあるミスと対策
journalctl の使い方を誤ると、トラブルシューティングの時間がかかる原因になります。
ここでは、実際に起こった失敗事例とその対策を紹介します。
ケース1:ログを適切に絞り込まず、大量のログを表示してしまった
運用中のアプリケーションで障害が発生し、journalctl でログを調査しようとしたところ、大量のログが表示されてしまい、量が多くネットワークトラフィックを圧迫してしまいました。
失敗したコマンド
journalctl→ 数十万行のログが出力され、目的のログを見つけられなかった
正しい方法
1.直近のログのみ表示
journalctl -n 502.特定の時間帯のログを検索
journalctl --since "2024-03-01 12:00:00" --until "2024-03-01 14:00:00"journalctl を実行したらログが多すぎて見切れません!
-n 50 や --since を使って、必要な範囲だけ表示しよう。

ケース2:誤ったサービス名を指定し、ログが取得できなかった
特定のサービスのエラーログを調査しようとして、誤ったサービス名を指定してしまった経験があります。
失敗したコマンド
journalctl -u nginx.service→ 「No entries found」エラー発生
正しい方法 サービス名を正しく指定
journalctl -u nginx→ systemctl list-units --type=service で正しい名前を確認可能
特定のサービスのログが取れません!
systemctl list-units --type=service で正しい名前を確認しよう。

まとめ|journalctl コマンドを使いこなすために
journalctl コマンドは Linux システムのトラブルシューティングに不可欠なツールです。
しかし、適切にフィルタリングしないと、目的のログを素早く取得できず、調査に時間がかかることになります。
journalctl を効果的に活用するポイント
-u [サービス名]で特定のサービスのログを取得-p [優先度]を活用し、エラーレベルごとに絞り込む--sinceや-n [件数]でログの範囲を限定する- 正しいサービス名を確認し、誤った指定をしない
- リアルタイム監視 (
-fオプション) を活用する
journalctl を使いこなせば、トラブル対応がもっと速くなりますか?
間違いなく速くなるよ!適切なフィルタリングとオプションを活用すれば、ログ解析のスピードが格段に上がる。
journalctl を活用し、システムトラブルに素早く対応できるエンジニア を目指しましょう!



ゴリタン
インフラエンジニアとして、ネットワークとサーバーの運用・保守・構築・設計に幅広く携わり、
現在は大規模政府公共データの移行プロジェクトを担当。
CCNPやLPICレベル3、AWSセキュリティスペシャリストなどの資格を保有しています。