

最終更新日 2025年3月10日

本記事の要点
dmesgコマンドの基本構文
dmesg [オプション]dmesgでよく使用するオプション
| オプション | 説明 |
|---|---|
| dmesg | カーネルメッセージバッファを表示 |
| dmesg -C | メッセージバッファをクリア |
| dmesg -T | メッセージのタイムスタンプを人間が読みやすい形式で表示 |
| dmesg -k | カーネルメッセージのみ表示 |
| dmesg -l err | エラーメッセージのみ表示 |
| dmesg -l warn | 警告メッセージのみ表示 |
| dmesg -l info | 情報メッセージのみ表示 |
| dmesg -n 1 | 表示するログレベルを制限(ここでは1=KERN_EMERG) |
| dmesg -H | 出力を読みやすい形式にフォーマット |
| dmesg -x | 詳細なフォーマットで出力 |
| dmesg -w | リアルタイムでメッセージを監視 |
| dmesg | tail -n 20 | 最新の20行を表示 |
| dmesg | grep 'error' | エラーメッセージのみ抽出 |
| dmesg -f kern | 特定のファシリティ(ここではkern)に絞って表示 |
| dmesg --color=always | 色付き出力(サポートされている環境のみ) |
dmesgの出力結果の意味
実行コマンド
dmesg | tail -n 5出力結果
[ 123.456789] usb 1-1: new high-speed USB device number 2 using xhci_hcd
[ 124.123456] eth0: Link is Up - 1Gbps/Full - flow control rx/tx
[ 125.987654] CPU1: Core temperature above threshold, CPU throttled
[ 126.543210] EXT4-fs (sda1): mounted filesystem with ordered data mode. Opts: (null)
[ 127.678901] random: crng init done| 項目 | 意味 |
|---|---|
| [ 123.456789] | タイムスタンプ(システム起動からの経過時間、秒単位) |
| usb 1-1: new high-speed USB device | USBデバイスの接続情報 |
| eth0: Link is Up | ネットワークインターフェースの状態 |
| CPU1: Core temperature above threshold | CPU温度の警告 |
| EXT4-fs (sda1): mounted filesystem | ファイルシステムのマウント情報 |
| random: crng init done | 乱数生成の初期化完了 |
dmesgコマンドとは?Linuxでの役割と基本概要
本セクションでは以下の内容について解説します。
dmesgの基本機能と役割
dmesg(display message)コマンドは、Linuxカーネルが出力するログメッセージを表示するためのコマンドです。
主にシステムの起動時の情報やハードウェアの状態、ドライバの動作ログを確認するために使用されます。これにより、システムの異常やエラーを検知しやすくなります。
先輩、dmesg ってどんなコマンドなんですか?
dmesg はカーネルが出力するログメッセージを表示するコマンドだよ。システムの起動時やデバイスの接続時、エラー発生時などにカーネルが出力する情報を取得できるんだ。
journalctl と dmesg って何が違うんですか?
dmesg はカーネルメッセージのみを出力するのに対し、journalctl はシステム全体のログを管理する。例えば、dmesg でデバイスのエラーメッセージを確認し、journalctl でシステムログ全体の流れを把握する、といった使い方ができるよ。

なぜdmesgが重要なのか?(カーネルログの役割)
dmesgはLinuxカーネルがリアルタイムで記録する重要な情報源であり、システム管理者や開発者がトラブルシューティングを行う際に欠かせないツールです。
特に以下のような場面で役立ちます。
- システムの起動ログの確認(ブート時のエラーや遅延の原因調査)
- ハードウェアの認識状況のチェック(USBやディスクの接続状況)
- ドライバの読み込み状況の確認(モジュールのエラーやロード状態)
- カーネルのエラーメッセージの確認(Kernel Panic、OOM Killerの発動など)
カーネルログって、システム運用でそんなに重要なんですか?
すごく重要だよ。例えば、USBメモリを挿しても認識しない時、dmesg を見れば原因がわかることがあるし、カーネルパニックの原因も確認できる。ハードウェアの問題を特定するのにも役立つんだ。
dmesgを利用するメリット
1. システムの異常を素早く検知できるdmesg を使えば、カーネルが出力するエラーや警告をリアルタイムで確認できるため、問題の原因を素早く特定できます。
2. ハードウェアの動作状況を簡単にチェックできる
新しいデバイスを接続したとき、dmesg を実行することでデバイスが正しく認識されているか確認できます。特にUSBデバイスやSSD、メモリ関連の問題を特定するのに便利です。
3. シンプルなコマンドで扱いやすいdmesg はコマンド一つでカーネルログを出力でき、grep などのコマンドと組み合わせて簡単にログをフィルタリングできます。
でも、システムログなら /var/log/messages や journalctl を見ればいいんじゃないですか?
それもいいけど、dmesg はカーネルメッセージに特化しているから、特にハードウェアやドライバの問題を調査するのに向いているんだ。カーネルのエラーやドライバの読み込み状況を確認するなら、まず dmesg をチェックするのが定石だよ。
まとめ
dmesgはカーネルのログメッセージを表示するコマンド- システムの異常検知やハードウェアの状態確認に便利
journalctlとは用途が異なり、カーネルに特化した情報を取得できる- シンプルなコマンドで、トラブルシューティングに必須のツール
Linux dmesgコマンドの基本的な使い方
本セクションでは以下の内容について解説します。
dmesgコマンドの基本構文
dmesg コマンドは、Linuxカーネルが出力するログメッセージを表示するためのシンプルなコマンドです。基本的には dmesg を実行するだけで、最新のカーネルログを確認できます。
dmesg [オプション]主なオプション
-T:ログのタイムスタンプを人間が読みやすい形式に変換-c:現在のカーネルログを表示後にクリア-H:ログをハイライト表示(色付き)-l <レベル>:特定のログレベル(エラーや警告のみなど)を表示--color=always:色付きで出力
dmesg を実行したら大量のログが出るんですが、どうやって必要な情報を探せばいいですか?
まずは dmesg | less でスクロールしながら見てみるといいよ。特定のキーワードで絞り込みたいなら grep を使うと便利だ。
![dmesgコマンドの基本構文
基本的な使い方
dmesg [オプション]
主なオプション
-T:タイムスタンプを人間が読みやすい形式に変換
-c:現在のカーネルログを表示後にクリア
-H:ログをハイライト表示(色付き)
-l <レベル>:特定のログレベルを表示
基本コマンド例
dmesg -T(読みやすい時間形式で表示)](https://www.goritarou.com/wp-content/uploads/2025/03/image-16-1024x466.png)
dmesgコマンドの使い方(カーネルログの表示)
基本的な dmesg の使い方は、単にコマンドを実行することです。これでシステムのカーネルメッセージ全体を表示できます。
dmesgただし、デフォルトではUNIXタイム(秒数)で表示されるため、ログの時間が分かりにくい です。その場合は -T オプションを使います。
dmesg -Tログの時間が 1643291345.123456 みたいに表示されるんですが、これってどう読むんですか?
それはUNIXタイムと呼ばれる形式だから、人間が読みやすい YYYY-MM-DD HH:MM:SS に変換するには dmesg -T を使うといいよ。
ログのフィルタリング方法(grepとの組み合わせ)
dmesg はそのままだと大量の情報が表示されるため、grep を使って特定の情報を絞り込むのが基本です。
例えば、エラーメッセージ(error)だけを表示 する場合
dmesg | grep -i "error"また、警告(warning)メッセージを確認 するには:
dmesg | grep -i "warning"デバイスのログだけを見たいんですが、どうやって絞り込めばいいですか?
USBなら dmesg | grep -i usb、ネットワークなら dmesg | grep -i eth のように、関連するキーワードを指定するといいよ。

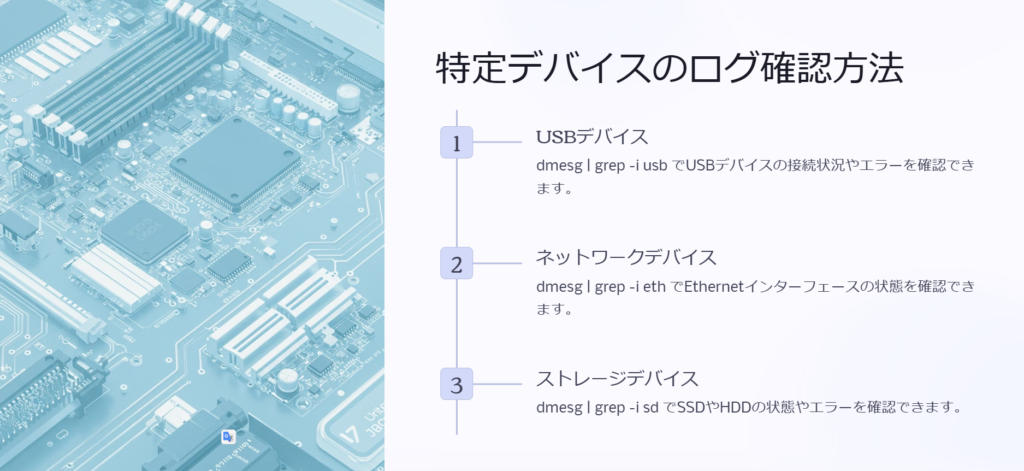
特定のデバイスのログを確認する方法
特定のハードウェアデバイスのログを確認するには、デバイス名やキーワードを指定して絞り込む のが効果的です。
USBデバイスのログを確認する
dmesg | grep -i usbネットワークデバイス(Ethernet)のログを確認する
dmesg | grep -i ethストレージデバイス(SSDやHDD)のログを確認する
dmesg | grep -i sd新しくUSBデバイスを挿したんですが、認識されているか確認する方法はありますか?
まず dmesg | grep -i usb を実行して、新しいデバイスの接続メッセージが出ているか確認してみよう。次に lsblk でデバイス名をチェックすると、ちゃんと認識されているか分かるよ。
起動ログを確認する方法
システムの起動時のメッセージを確認するには、ブート時のログだけを抽出 するオプション -k を使います。
dmesg --level=err,warnまた、システム起動後のイベントも確認 するには、ログレベルを指定して重要なメッセージのみを表示すると便利です。
dmesg --level=crit,alert,emergシステムが正常に起動したか確認したいんですが、どこを見ればいいですか?
dmesg | grep -i "error\|fail" でエラーを確認し、dmesg -T | less でブートシーケンスを確認するといいよ。特に systemd のメッセージも合わせて journalctl -b で見ると、より詳細な情報が分かる。

まとめ
dmesgはLinuxのカーネルログを取得するコマンド- 基本的な使い方は
dmesgまたはdmesg -T - エラーやデバイスごとのログを
grepで絞り込むのが実用的 - USBやネットワーク、ストレージのログを確認する際に活用できる
- 起動時のログは
dmesg --level=err,warnでチェックできる
dmesgのログ解析と応用テクニック
本セクションでは以下の内容について解説します。
カーネルメッセージの見方と解釈
dmesg のログはカーネルが出力するシステム情報やエラーメッセージが含まれていますが、適切に解釈することが重要です。基本的なフォーマットを理解すれば、トラブルシューティングやパフォーマンス監視に役立ちます。
dmesg の出力は以下のような形式になっています。
[ 123.456789] usb 1-1: new high-speed USB device number 3 using ehci-pci[ 123.456789]→ カーネル起動後の時間(秒)usb 1-1:→ 対象となるデバイス(この場合はUSB)new high-speed USB device number 3 using ehci-pci→ イベントの詳細
dmesg のログの時間って、リアルな時刻じゃないんですね?
そうだね。デフォルトではカーネルの起動時間からの経過秒数で表示されるから、リアルな時刻にしたいときは dmesg -T を使うといいよ。
![カーネルメッセージの見方と解釈
時間情報
[ 123.456789] はカーネル起動後の経過時間(秒)を示します。
対象デバイス
usb 1-1: のように、メッセージが関連するデバイスやサブシステムが表示されます。
イベント詳細
new high-speed USB device number 3 using ehci-pci のように、具体的な情報が表示されます。](https://www.goritarou.com/wp-content/uploads/2025/03/image-20-1024x468.png)
ログの時刻情報を見やすくする方法(dmesg -T)
デフォルトの dmesg の時刻は、カーネル起動後の経過時間で表示されるため、人間が理解しやすい形式に変換するには -T オプションを使用します。
dmesg -T実行結果
[Fri Mar 1 12:34:56 2024] usb 1-1: new high-speed USB device number 3 using ehci-pciリアルタイムの時刻が表示されるのは便利ですね!でも、-T で変換された時間って正確なんですか?
基本的にはシステムクロックに基づいて変換されるけど、まれにズレが生じることもある。正確な時刻情報が必要なときは journalctl のほうが適しているよ。
![ログの時刻情報を見やすくする方法
デフォルト表示
[ 123.456789] usb 1-1: new high-speed USB device number 3 using ehci-pci
カーネル起動後の経過時間(秒)で表示されます。
-T オプション使用時
[Fri Mar 1 12:34:56 2024] usb 1-1: new high-speed USB device number 3 using ehci-pci
人間が読みやすい日時形式に変換されます。](https://www.goritarou.com/wp-content/uploads/2025/03/image-21-1024x323.png)
エラーメッセージの種類と対処法
dmesg のエラーメッセージは、システムの異常や障害を特定するために重要な情報です。特定のエラーだけを抽出するには --level オプションを使います。
dmesg --level=err,warnよくあるエラーメッセージ
| メッセージ | 内容 | 対処方法 |
|---|---|---|
| I/O error | デバイスの読み書きエラー | デバイスの接続確認・fsckの実行 |
| Out of memory | メモリ不足エラー | 使用中プロセスの確認・スワップ拡張 |
| Kernel panic | カーネルクラッシュ | エラーログ解析・ハードウェアチェック |
| Failed to mount | マウント失敗 | fstab設定の確認・デバイスの状態チェック |
Out of memory: Killed process というエラーが出てるんですが、これってどういう意味ですか?
これはシステムのメモリが不足して、カーネルが強制的にプロセスを終了させたことを意味しているよ。まず free -h でメモリ状況を確認して、不要なプロセスを kill したり、スワップ領域を増やしたりするといい。

ログをファイルに保存する方法
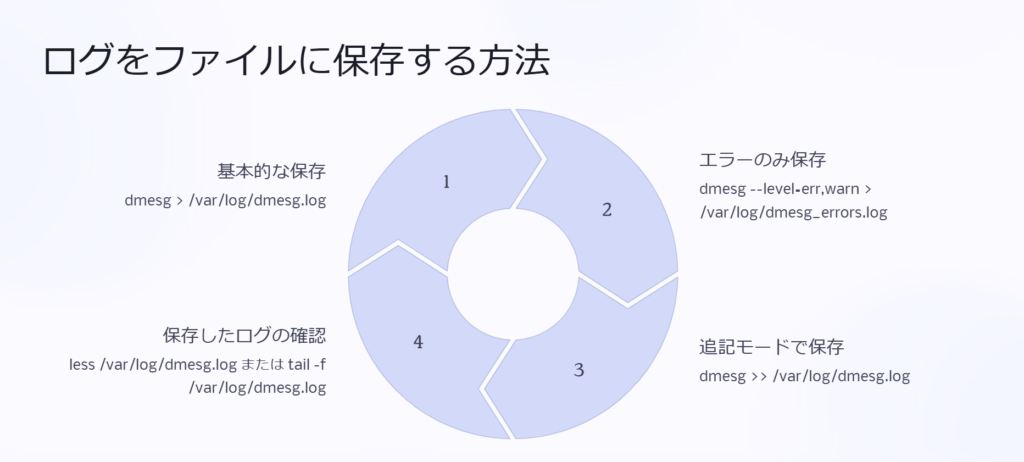
dmesg の出力を後で分析したり、共有するためにファイルに保存する方法を知っておくと便利です。
ファイルにログを保存
dmesg > /var/log/dmesg.logまたは、特定のエラーだけを保存する場合は以下です。
dmesg --level=err,warn > /var/log/dmesg_errors.logログを追記モードで保存
dmesg >> /var/log/dmesg.log保存したログを後で簡単に確認する方法ってありますか?
less /var/log/dmesg.log を使うとスクロールしながら見られるよ。リアルタイムで監視するなら tail -f /var/log/dmesg.log もおすすめだ。
システムトラブルの早期発見に役立つ活用例
デバイスの異常検知
新しいデバイスを接続しても認識されない場合
dmesg | grep -i usbメモリ不足の監視
OOM (Out of Memory) が発生していないか確認する
dmesg | grep -i "out of memory"カーネルパニックの原因特定
システムがクラッシュした場合の原因を調査する
dmesg | grep -i "kernel panic"システムが不安定なんですが、dmesg を使って何をチェックすればいいですか?
まず dmesg --level=err,warn でエラーを確認しよう。ハードウェア関連なら dmesg | grep -i usb や dmesg | grep -i ata でデバイスの問題を調べるのが基本だね。

まとめ
- dmesg のログはカーネルの動作を記録する重要な情報源
dmesg -Tを使うと、ログの時刻を人間が読みやすい形式に変換できる- エラーメッセージを
--level=err,warnで抽出し、トラブルシューティングに活用 - ログをファイルに保存して分析したり、システム監視に役立てることができる
- dmesg を活用することで、ハードウェアトラブルやカーネルクラッシュの原因を素早く特定できる
dmesgコマンドを活用したトラブルシューティング
本セクションでは以下の内容について解説します。
ハードウェアの問題を特定する方法(ディスク・メモリ・USBデバイス)
dmesg を使用すると、ハードウェアの問題(ディスク、メモリ、USBデバイス)のエラーや認識状況を素早く確認できます。特定のデバイスに関するログを抽出し、問題を特定することが重要です。
ディスク(HDD・SSD)のエラーを確認
ディスク関連のエラーを調べるには、以下のコマンドを実行します。
dmesg | grep -i "sd"エラーメッセージ
[ 1234.56789] sd 0:0:0:0: [sda] Unhandled sense code最近サーバーのディスクI/Oが遅いんですが、dmesgでチェックできますか?
まず dmesg | grep -i sd でディスク関連のエラーを確認しよう。特に I/O error や bad sector というメッセージが出ていたら、ディスクに異常がある可能性が高いね。
![ディスク関連の問題を特定する方法
ディスクエラーの確認
dmesg | grep -i "sd" でディスク関連のエラーを調べられます。
エラーメッセージの例
[ 1234.56789] sd 0:0:0:0: [sda] Unhandled sense code
対処方法
smartctl -a /dev/sda でディスクの状態を確認し、fsck -y /dev/sda1 でファイルシステムを修復します。](https://www.goritarou.com/wp-content/uploads/2025/03/image-25-1024x450.png)
メモリの問題を特定
メモリ関連のエラーログを確認するには
dmesg | grep -i "memory"また、OOM(Out of Memory)エラーの確認
dmesg | grep -i "oom"プロセスが勝手に落ちるんですが、メモリ不足が原因かどうか調べられますか?
dmesg | grep -i oom を実行して、OOM Killer が発動していないか確認しよう。もしメモリ不足なら、スワップの増設や不要なプロセスの削除を検討するといいよ。

USBデバイスが認識されない場合
USB関連のログを確認するには
dmesg | grep -i usbUSBデバイスを挿しても認識されません。何をチェックすればいいですか?
まず dmesg | grep -i usb で、新しいデバイスの認識ログが出ているか確認しよう。もし device not accepting address のようなエラーが出ていたら、ポートやデバイスの問題の可能性が高いね。
ネットワークトラブルをdmesgで解析する方法
ネットワークのトラブルシューティングでは、dmesg でネットワークデバイス(eth0 など)のエラーメッセージを確認するのが有効です。
ネットワークインターフェースの状態を確認
dmesg | grep -i "eth"エラーメッセージ
[ 3456.78901] e1000: eth0: Link is Downサーバーのネットワークが不安定なんですが、原因を調べるにはどうすればいいですか?
まず dmesg | grep -i eth でネットワークインターフェースのエラーログを確認しよう。Link is Down のようなメッセージが出ていたら、ケーブルやスイッチの接続状態もチェックするべきだね。

ドライバのロードエラーを確認
dmesg | grep -i "firmware"ネットワークドライバの読み込みに失敗している場合、firmware failed to load というエラーが出ることがあります。
新しいネットワークアダプタを追加したら、うまく動かないんですが?
dmesg | grep -i firmware でドライバの読み込みエラーがないか確認しよう。もし failed to load のようなメッセージが出ていたら、対応するファームウェアをインストールする必要があるかもしれないね。
カーネルクラッシュ(Kernel Panic)のログを確認する方法
Kernel Panic が発生すると、システムが停止し、再起動しないと復旧できないことがあります。dmesg を使ってクラッシュの原因を調べることが重要です。
Kernel Panic のログを確認
dmesg | grep -i "panic"または、直近のクラッシュログを表示
journalctl -k -b -1サーバーが突然落ちて、Kernel Panic のメッセージが出たんですが、原因を特定する方法はありますか?
dmesg | grep -i panic で、クラッシュ前のログを確認してみよう。特に fatal exception や unable to handle kernel paging request というメッセージが出ていたら、メモリやカーネルの問題の可能性があるね。

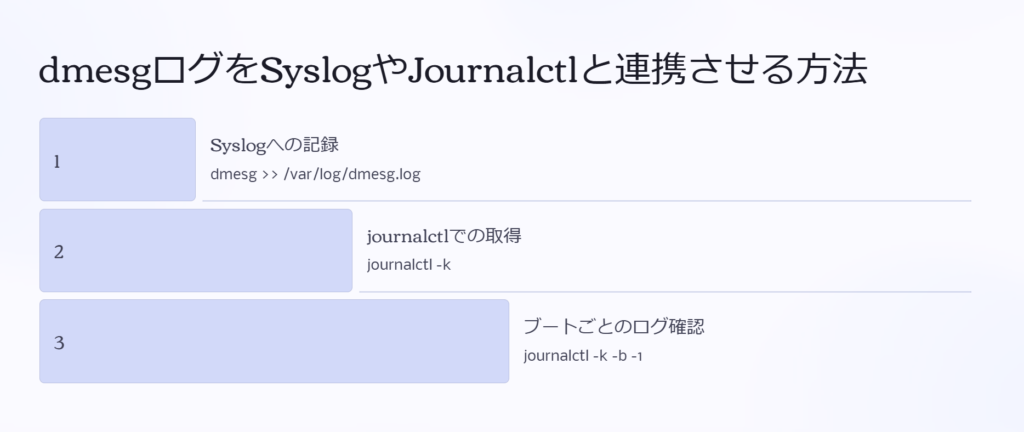
dmesgログをSyslogやJournalctlと連携させる方法
dmesg は一時的なカーネルログを表示するだけなので、ログを長期的に管理したい場合は Syslog や Journalctl との連携が必要です。
Syslog(/var/log/messages)にdmesgを記録
通常、カーネルログは /var/log/messages や /var/log/syslog に記録されます。手動で追加する場合以下のコードを実行しいます。
dmesg >> /var/log/dmesg.logjournalctl でカーネルログを取得
journalctl -kブートごとのログを確認するには以下のコードを実行します。
journalctl -k -b -1dmesg のログって再起動すると消えるんですよね?過去のログはどうやって見ればいいですか?
そうだね。過去のログを見たいなら journalctl -k -b -1 を使うと、前回の起動時のカーネルメッセージを確認できるよ。
まとめ
- dmesg を使えばハードウェアの問題(ディスク、メモリ、USB)を素早く特定できる
- ネットワークトラブルの解析には
dmesg | grep -i ethでインターフェース状態を確認する - Kernel Panic のログを
dmesg | grep -i panicで特定し、クラッシュの原因を分析する - Syslog や Journalctl と連携すると、再起動後もカーネルログを管理できる
よくあるdmesg関連のエラーと対処法
本セクションでは以下の内容について解説します。
- 「buffer I/O error」エラーの原因と解決策
- 「failed to mount root fs」エラーのトラブルシューティング
- 「Out of memory: Killed process」エラーの対応策
- 「Kernel panic」発生時の対処方法
- まとめ
「buffer I/O error」エラーの原因と解決策
「buffer I/O error」 は、ディスクやストレージデバイスの読み書きエラーを示すメッセージです。ハードウェアの故障、ファイルシステムの破損、不良セクタなどが原因として考えられます。
エラーメッセージ
[ 1234.567890] buffer I/O error on device sda1, logical block 12345原因と対策
| 原因 | 対策 |
|---|---|
| 物理的なディスク障害 | smartctl -a /dev/sda でディスクの状態を確認し、不良セクタが多い場合は交換を検討 |
| ファイルシステムの破損 | fsck -y /dev/sda1 を実行し、エラーを修復 |
| ケーブルや接続の問題 | SATA / USB ケーブルを交換し、再接続 |
ディスクの読み書きエラーが出ています。これってディスクの故障ですか?
smartctl -a /dev/sda でディスクの状態を確認しよう。不良セクタが増えているなら故障の可能性が高いね。ファイルシステムの破損なら fsck で修復できるか試してみよう。
「failed to mount root fs」エラーのトラブルシューティング
「failed to mount root fs」 エラーは、システムのルートファイルシステムが正常にマウントできないときに発生します。ブートプロセスが停止し、OSが起動できなくなる重大なエラーです。
エラーメッセージ
[ 5678.910111] VFS: Cannot open root device "sda1" or unknown-block(0,0)
[ 5678.910112] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)原因と対策
| 原因 | 対策 |
|---|---|
| fstabの設定ミス | cat /etc/fstab で設定を確認し、UUIDまたはデバイス名が正しいか確認 |
| ファイルシステムの破損 | fsck -y /dev/sda1 を実行して修復 |
| カーネルが適切なドライバをロードしていない | initrd を更新 (update-initramfs -u) |
OSがブートしなくなって、『failed to mount root fs』 というエラーが出ています。どうすればいいですか?
まず fsck -y /dev/sda1 でファイルシステムを修復してみよう。それでもダメなら cat /etc/fstab で設定ミスがないか確認してみて。
「Out of memory: Killed process」エラーの対応策
「Out of memory: Killed process」エラーは、システムのメモリ不足が原因で、カーネルが特定のプロセスを強制終了(OOM Killerの発動)したことを示します。特に負荷の高いプロセスがあると発生しやすくなります。
エラーメッセージ
[ 6789.123456] Out of memory: Killed process 1234 (java) total-vm:5123456kB, anon-rss:204800kB, file-rss:1024kB原因と対策
| 原因 | 対策 |
|---|---|
| メモリ消費の多いプロセスがある | top や htop でプロセスを確認し、不必要なプロセスを終了 |
| スワップ領域が不足している | swapon -s でスワップの使用状況を確認し、必要ならスワップを増設 |
| メモリリークの可能性 | `dmesg |
Out of memory: Killed process というエラーが出て、アプリケーションが勝手に落ちてしまいます。
top でメモリを大量に消費しているプロセスを特定しよう。スワップが少ないなら swapon -s で確認して増設するのも手だね。
「Kernel panic」発生時の対処方法
「Kernel panic」 は、カーネルが回復不能なエラーに直面し、システムが停止したことを示します。再起動しない限り復旧できません。発生原因を特定し、適切に対処することが重要です。
エラーメッセージ
[ 7890.234567] Kernel panic - not syncing: Fatal exception in interrupt原因と対策
| 原因 | 対策 |
|---|---|
| ハードウェア障害 | `dmesg |
| メモリの不具合 | memtest86+ を実行してメモリチェック |
| カーネルアップデート後の不具合 | grub で前のカーネルに戻す (grub menu から起動) |
| 不正なカーネルパラメータ | cat /proc/cmdline で起動オプションを確認 |
Kernel Panic が発生してサーバーが止まりました。原因を調べるにはどうすればいいですか?
dmesg -T | grep -i panic で直前のエラーを確認しよう。メモリ関連なら memtest86+ でチェック、それでもダメなら grub から前のカーネルを試してみるといい。
まとめ
- 「buffer I/O error」 はディスクの読み書きエラー。
smartctlやfsckでチェック - 「failed to mount root fs」 はルートファイルシステムのマウント失敗。
fsckやfstabの確認が必要 - 「Out of memory: Killed process」 はメモリ不足。
topでプロセス確認やスワップ増設が有効 - 「Kernel panic」 はカーネルの致命的エラー。
dmesg | grep panicで原因を特定
dmesgコマンドを使いこなすためのTIPS
dmesgの出力は大量のテキスト情報を含むため、色分けすると重要なメッセージを素早く識別しやすくなります。Linuxでは ccze や kmsg などのツールを使うことで、dmesgの出力をカラー表示できます。

cczeを使ってカラフルな出力にする
dmesg | ccze -Admesgのログって見づらいですよね。エラーメッセージだけ目立たせる方法はありますか?
ccze を使うとログを色分けできて、エラーや警告が視覚的に分かりやすくなるよ。まず sudo apt install ccze でインストールしてみよう。
dmesgをリアルタイムで監視する方法
システムの状態をリアルタイムで監視するには、dmesg -w を使うのが有効です。新しいログが発生するたびに自動的に表示されるため、システムの異常を即座に検知できます。
dmesg -wUSBデバイスを抜き差しした時に、すぐにログを確認する方法ってありますか?
dmesg -w を実行しておくと、リアルタイムで新しいログが表示されるよ。USBを接続した瞬間に出力されるログを見て、認識されているか確認できるね。
cronジョブを使った定期的なログ記録と解析
dmesgのログを定期的に記録し、異常を自動検出するには cron を使ってログを保存し、特定のエラーを監視するのが有効です。
dmesgログを定期的に保存
crontab -e以下の行を追加(毎時 dmesg のログを保存)
0 * * * * dmesg > /var/log/dmesg.log特定のエラーを検出するスクリプト
例えば、「I/Oエラー」を監視してメール通知するスクリプト
#!/bin/bash
if dmesg | grep -q "I/O error"; then
echo "I/O error detected" | mail -s "dmesg Alert" admin@example.com
fiシステムが異常を検出したら、自動で通知する方法はありますか?
cronジョブで dmesg のエラーログを定期的にチェックして、異常が見つかったらメールで通知するスクリプトを作るといいよ。
dmesgを活用した特殊事例
一般的なハードウェア障害やメモリ不足のトラブルシューティングはよくありますが、Linuxシステムを運用していると、より特殊で珍しい問題にも遭遇することがあります。ここでは、実際に発生した特殊な事例と、その解決プロセスを紹介します。
幽霊デバイス?突然増殖するネットワークインターフェース
症状
ある日、仮想環境で運用しているLinuxサーバーの ifconfig を確認すると、見覚えのない “eth1”、“eth2” というネットワークインターフェースが増えていました。しかし、設定ファイル (/etc/network/interfaces) には存在しないはずのインターフェースでした。
調査開始
すぐに dmesg | grep -i eth を実行し、ネットワークデバイスの挙動を確認しました。すると、次のようなログが出力されました。
[ 8765.4321] e1000: eth1: renamed from eth0
[ 8765.4322] e1000: eth2: renamed from eth1どうやら カーネルが勝手にインターフェースの名前を変更し続けている ようでした。
原因
- 物理NICのMACアドレスが変わった際、
udevルールが誤って適用され、新しいデバイスとして認識された。 /etc/udev/rules.d/70-persistent-net.rulesに古いインターフェースの設定が残っており、新たな名前が付与され続けていた。
解決策
ls /etc/udev/rules.d/で70-persistent-net.rulesを確認。- ルールファイルを削除し、
udevadm control --reload-rulesでルールを再読み込み。 - サーバーを再起動すると、正しく
eth0のみが認識されるようになった。
「dmesg の renamed from メッセージを見逃さなかったことで、udev の誤作動に気づくことができました。ネットワークインターフェースの増殖現象に遭遇したら、まず dmesg を確認すると良いですね。」
なぜか特定の時間にCPU使用率100%になる怪現象
症状
あるLinuxサーバーが 毎日深夜3時 になると、CPU使用率が100%になり、動作が極端に遅くなる現象が発生していました。top コマンドで確認すると、特定のプロセスが高負荷を引き起こしているわけではなく、CPU全体の負荷が急上昇していました。
調査開始
dmesg -T | grep -i "thermal" を実行し、CPUの温度に関連するログを確認したところ、次のようなメッセージが表示されました。
[Sun Mar 3 03:00:01 2024] CPU1: Core temperature above threshold, CPU throttled
[Sun Mar 3 03:00:02 2024] CPU1: Core temperature normalこのログから、CPUが過熱し、スロットリング(クロック速度を制限)されていた ことが判明しました。
原因
- 深夜3時に RAIDの自動リビルド が実行され、それによってCPUとディスクI/Oが急激に増加。
- CPUクーラーの冷却能力が限界に達し、温度が閾値を超えたため、カーネルがスロットリングを実施。
解決策
dmesg -T | grep -i "raid"でRAIDの動作ログを確認し、確かに3時にリビルドが実行されていることを特定。- RAIDのスケジュールを変更し、CPU負荷が少ない時間帯に変更 (
/etc/cron.d/mdadmを編集)。 - CPUクーラーの清掃とサーマルペーストの再塗布を実施。
「RAIDリビルドとCPUスロットリングの関係を dmesg で発見できました。定期的な高負荷タスクがハードウェアに与える影響を考慮するのは重要ですね。
USBメモリが抜けても認識されたままになる奇妙な現象
症状
サーバーにUSBメモリを挿入し、umount した後に取り外したにもかかわらず、lsblk や df コマンドではまだデバイスがマウントされていると表示されていました。
調査開始
dmesg | grep -i usb を実行すると、以下のようなログが表示されました。
[ 2345.678901] usb 2-1: USB disconnect, device number 5
[ 2345.678902] usb 2-1: device not properly removed, residual connection detectedこのログから、USBメモリが適切に「取り外し」処理されなかった ことが分かりました。
原因
- USBメモリが適切に
syncされず、カーネルが未処理のデータを保持したままになっていた。 umountは実行されたが、カーネルがデバイスの「切断」を認識していなかった。
解決策
syncを手動で実行:bashコピーする編集するsyncecho 1 > /sys/block/sdb/device/deleteでカーネルからデバイス情報を削除:bashコピーする編集するecho 1 > /sys/block/sdb/device/deletedmesgを再確認し、正常にデバイスが削除されたことを確認:yamlコピーする編集する[ 2346.123456] usb 2-1: device removed successfully
「USBデバイスが適切に取り外されなかったときは、dmesg で device not properly removed のメッセージを確認し、カーネル側の処理を手動で修正できることを学びました。」
まとめ
- ネットワークインターフェースが勝手に増殖する問題 →
dmesgのrenamed fromメッセージでudevの影響を特定。 - 特定の時間にCPUがスロットリングする問題 →
dmesg | grep -i thermalで温度異常を検知し、RAIDリビルドの影響と判明。 - USBメモリを抜いても認識されたままの問題 →
dmesgでdevice not properly removedを確認し、手動でデバイスを削除。
dmesg はハードウェアの異常だけでなく、システム内部の動作やカーネルの挙動を可視化する強力なツール です。通常のログには記録されないような問題でも、dmesg を活用することで、原因を突き止めることができます。システムの挙動が「おかしい」と思ったら、まず dmesg を確認する習慣をつけることが、迅速な問題解決につながります。


ゴリタン
インフラエンジニアとして、ネットワークとサーバーの運用・保守・構築・設計に幅広く携わり、
現在は大規模政府公共データの移行プロジェクトを担当。
CCNPやLPICレベル3、AWSセキュリティスペシャリストなどの資格を保有しています。